textgeneration中文模型版
上次我们安装了textgeneration,但它对中文支持不是很友好,现在我们需要去下载一个中文模型,
由于没有现成的中文模型可用,只能自己通过github开源的项目来合并模型后使用,下面介绍怎么去合并模型:
github地址:
https://github.com/ymcui/Chinese-LLaMA-Alpaca.git
如果觉得下载速度慢可关注我公众号领取百度云链接去下载哦!
本公众号还接入了chatgpt最新版哦!

1.下载模型文件 Chinese-Alpaca-7B和Chinese-Alpaca-13B并解压
压缩包内文件目录如下(以Chinese-LLaMA-7B为例):
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
以下是各原模型和4-bit量化后的大小,转换相应模型时确保本机有足够的内存和磁盘空间(最低要求):
| 7B | 13B | 33B | 65B | |
|---|---|---|---|---|
| 原模型大小(FP16) | 13 GB | 24 GB | 60 GB | 120 GB |
| 量化后大小(4-bit) | 3.9 GB | 7.8 GB | 19.5 GB | 38.5 GB |
2.准备工作
- 确保机器有足够的内存加载完整模型(例如7B模型需要13-15G)以进行合并模型操作。
- 务必确认基模型和下载的LoRA模型完整性,检查是否与SHA256.md所示的值一致,否则无法进行合并操作。
- 原版LLaMA包含:
tokenizer.model、tokenizer_checklist.chk、consolidated.00.pth、params.json
- 原版LLaMA包含:
- 主要依赖库如下:
- 最新版🤗Transformers,必须从源码安装,因为v4.27并不包含
LlamaModel等实现 sentencepiece(0.1.97测试通过)peft(0.2.0测试通过)
- 最新版🤗Transformers,必须从源码安装,因为v4.27并不包含
pip install git+https://ghproxy.com/https://github.com/huggingface/transformers
pip install sentencepiece
pip install peft
2.下载官方模型到服务器(官方模型7B和13B的文件)
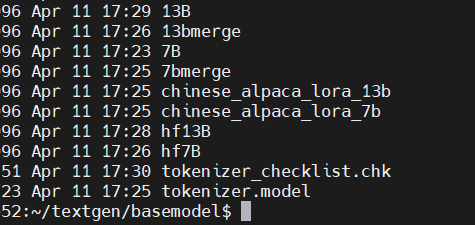
创建如下目录结构(basemodel目录下).
13B和7B目录对应官方模型
merge目录代表与中文模型合并后的目录
hf前缀目录代表将原版LLaMA模型转换为HF格式的目录
重点:当前目录下的tokennizer.model与tokennizer.checklist.chk为官方模型7B和13B同级的目录下的文件!
3.开始转换
在basemodel同级目录执行:
git clone https://ghproxy.com/https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
Step 1: 将原版LLaMA模型转换为HF格式
请使用最新版🤗transformers提供的脚本convert_llama_weights_to_hf.py,将原版LLaMA模型转换为HuggingFace格式。将原版LLaMA的tokenizer.model放在--input_dir指定的目录,其余文件放在${input_dir}/${model_size}下。执行以下命令后,--output_dir中将存放转换好的HF版权重。
7B
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /home/gt/textgen/basemodel \
--model_size 7B \
--output_dir /home/gt/textgen/basemodel/hf7B
13B
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /home/gt/textgen/basemodel \
--model_size 13B \
--output_dir /home/gt/textgen/basemodel/hf13B
可替换成自己的目录
Step 2: 合并LoRA权重,生成全量模型权重
这一步骤会对原版LLaMA模型(HF格式)扩充中文词表,合并LoRA权重并生成全量模型权重。此处可有两种选择:
- ✅ 需要量化部署:即输出PyTorch版本的权重(
.pth文件),使用scripts/merge_llama_with_chinese_lora.py脚本 - ❎ 不需要量化部署:即输出HuggingFace版本的权重(以便进一步进行精调),使用
scripts/merge_llama_with_chinese_lora_to_hf.py脚本(感谢@sgsdxzy 提供)
以上两个脚本需要设置的参数一致,只是输出文件格式不同。下面以“需要量化部署”为例,介绍相应的参数设置。
首先在basemodel下面创建两个文件夹用来存放合并后的文件,这里我们用merge文件夹
7B
python scripts/merge_llama_with_chinese_lora.py \
--base_model /home/gt/textgen/basemodel/hf7B \
--lora_model /home/gt/textgen/basemodel/chinese_alpaca_lora_7b \
--output_dir /home/gt/textgen/basemodel/7bmerge
13B
python scripts/merge_llama_with_chinese_lora.py \
--base_model /home/gt/textgen/basemodel/hf13B \
--lora_model /home/gt/textgen/basemodel/chinese_alpaca_lora_13b \
--output_dir /home/gt/textgen/basemodel/13bmerge
--base_model:存放HF格式的LLaMA模型权重和配置文件的目录(Step 1生成)--lora_model:将下载的中文LLaMA/Alpaca LoRA解压后文件所在目录,也可使用🤗Model Hub上的模型调用名称--output_dir:指定保存全量模型权重的目录,默认为./- (可选)
--offload_dir:对于低内存用户需要指定一个offload缓存路径
注意这里有坑,直接执行这个是会报错的!因为transformers目录下没有这个脚本!
先按如下执行,再执行上面的脚本。
在basemodel的同级目录下执行本操作!
git clone https://ghproxy.com/https://github.com/ymcui/Chinese-LLaMA-Alpaca.git
cd Chinese-LLaMA-Alpaca
这时候合并后的模型是不能直接使用的我们需要转换成本地部署可用的!先按下面操作。
接下来以llama.cpp工具为例,介绍MacOS和Linux系统中,将模型进行量化并在本地CPU上部署的详细步骤。Windows则可能需要cmake等编译工具的安装(Windows用户出现模型无法理解中文或生成速度特别慢时请参考FAQ#6)。本地快速部署体验推荐使用经过指令精调的Alpaca模型,有条件的推荐使用FP16模型,效果更佳。
下面以中文Alpaca-7B模型为例介绍,运行前请确保:
- 模型量化过程需要将未量化模型全部载入内存,请确保有足够可用内存(7B版本需要13G以上)
- 加载使用4-bit量化后的模型时(例如7B版本),确保本机可用内存大于4-6G(受上下文长度影响)
- 系统应有
make(MacOS/Linux自带)或cmake(Windows需自行安装)编译工具 - llama.cpp官方建议使用Python 3.9或3.10编译和运行该工具
Step 1: 克隆和编译llama.cpp
运行以下命令对llama.cpp项目进行编译,生成./main和./quantize二进制文件。
git clone https://ghproxy.com/https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
Step 2: 生成量化版本模型
根据需要转换的模型类型(LLaMA或Alpaca),将下载的LoRA模型压缩包中的tokenizer.model文件放入zh-models目录下,将合并模型中最后一步获取的模型文件consolidated.*.pth和配置文件params.json放入zh-models/7B目录下。请注意.pth模型文件和tokenizer.model是对应的,LLaMA和Alpaca的tokenizer.model不可混用(原因见训练细节)。目录结构类似:
llama.cpp/zh-models/
- 7B/
- consolidated.00.pth
- params.json
- tokenizer.model
7B转换和量化
需要将上面合并好的7bmerge目录放到zh-models目录下,并重命名为7B
mkdir -p /home/gt/textgen/llama.cpp/zh-models
mv /home/gt/textgen/basemodel/7bmerge /home/gt/textgen/llama.cpp/zh-models/7B
mv /home/gt/textgen/llama.cpp/zh-models/7B/tokenizer.model /home/gt/textgen/llama.cpp/zh-models/tokenizer.model
将上述.pth模型权重转换为ggml的FP16格式,生成文件路径为zh-models/7B/ggml-model-f16.bin。
cd /home/gt/textgen/llama.cpp
python convert-pth-to-ggml.py zh-models/7B/ 1
进一步对FP16模型进行4-bit量化,生成量化模型文件路径为zh-models/7B/ggml-model-q4_0.bin。
./quantize ./zh-models/7B/ggml-model-f16.bin ./zh-models/7B/ggml-model-q4_0.bin 3
此处也可以将最后一个参数改为3,即生成q4_1版本的量化权重。q4_1权重比q4_0大一些,速度慢一些,效果方面会有些许提升,具体可参考llama.cpp#PPL。
13B转换和量化
需要将上面合并好的7bmerge目录放到zh-models目录下,并重命名为7B
mkdir -p /home/gt/textgen/llama.cpp/zh-models
mv /home/gt/textgen/basemodel/13bmerge /home/gt/textgen/llama.cpp/zh-models/13B
mv /home/gt/textgen/llama.cpp/zh-models/13B/tokenizer.model /home/gt/textgen/llama.cpp/zh-models/tokenizer.model
将上述.pth模型权重转换为ggml的FP16格式,生成文件路径为zh-models/13B/ggml-model-f16.bin。
cd /home/gt/textgen/llama.cpp
python convert-pth-to-ggml.py zh-models/13B/ 1
进一步对FP16模型进行4-bit量化,生成量化模型文件路径为zh-models/13B/ggml-model-q4_0.bin。
./quantize ./zh-models/13B/ggml-model-f16.bin ./zh-models/13B/ggml-model-q4_0.bin 3
此处也可以将最后一个参数改为3,即生成q4_1版本的量化权重。q4_1权重比q4_0大一些,速度慢一些,效果方面会有些许提升,具体可参考llama.cpp#PPL。
Step 3: 加载并启动模型
运行./main二进制文件,-m命令指定4-bit量化模型(也可加载ggml-FP16的模型)。以下是解码参数示例:
7B
./main -m zh-models/7B/ggml-model-q4_0.bin --color -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3
13B
./main -m zh-models/13B/ggml-model-q4_0.bin --color -f prompts/alpaca.txt -ins -c 4096 --temp 0.2 -n 2048 --repeat_penalty 1.3
在提示符 > 之后输入你的prompt,cmd/ctrl+c中断输出,多行信息以\作为行尾。如需查看帮助和参数说明,请执行./main -h命令。下面介绍一些常用的参数:
-ins 启动类ChatGPT对话交流的运行模式
-f 指定prompt模板,alpaca模型请加载prompts/alpaca.txt
-c 控制上下文的长度,值越大越能参考更长的对话历史(默认:512)
-n 控制回复生成的最大长度(默认:128)
-b 控制batch size(默认:8),可适当增加
-t 控制线程数量(默认:4),可适当增加
--repeat_penalty 控制生成回复中对重复文本的惩罚力度
--temp 温度系数,值越低回复的随机性越小,反之越大
--top_p, top_k 控制解码采样的相关参数
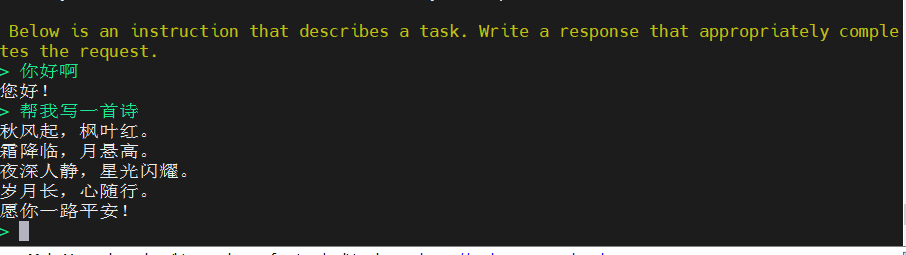
运行效果如下:

如果想在textgeneration下运行,可以把生成的模型复制到对应models目录下
mv /home/gt/textgen/llama.cpp/zh-models/7B /home/gt/text-generation-webui/models/
mv /home/gt/textgen/llama.cpp/zh-models/13B /home/gt/text-generation-webui/models/
如果webui想用4bit模型,需要做如下配置:
Step 0: install nvcc
conda activate textgen
conda install -c conda-forge cudatoolkit-dev
The command above takes some 10 minutes to run and shows no progress bar or updates along the way.
See this issue for more details: https://github.com/oobabooga/text-generation-webui/issues/416#issuecomment-1475078571
Step 1: install GPTQ-for-LLaMa
Clone GPTQ-for-LLaMa into the text-generation-webui/repositories subfolder and install it:
mkdir repositories
cd repositories
git clone https://ghproxy.com/https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda
cd GPTQ-for-LLaMa
python setup_cuda.py install
You are going to need to have a C++ compiler installed into your system for the last command. On Linux, sudo apt install build-essential or equivalent is enough.
Note: I am using my own fork of GPTQ-for-LLaMa until qwopqwop200's branch becomes more stable. It corresponds to commit a6f363e3f93b9fb5c26064b5ac7ed58d22e3f773 in the cuda branch of his repository.
Step 2: get the pre-converted weights
- Converted without
group-size(better for the 7b model): https://github.com/oobabooga/text-generation-webui/pull/530#issuecomment-1483891617 - Converted with
group-size(better from 13b upwards): https://github.com/oobabooga/text-generation-webui/pull/530#issuecomment-1483941105
Step 3: Start the web UI:
For the models converted without group-size:
python server.py --model llama-7b-4bit --wbits 4
For the models converted with group-size:
python server.py --model llama-13b-4bit-128g --wbits 4 --groupsize 128
CPU offloading
It is possible to offload part of the layers of the 4-bit model to the CPU with the --pre_layer flag. The higher the number after --pre_layer, the more layers will be allocated to the GPU.
With this command, I can run llama-7b with 4GB VRAM:
python server.py --model llama-7b-4bit --wbits 4 --pre_layer 20
This is the performance:
Output generated in 123.79 seconds (1.61 tokens/s, 199 tokens)
linux上构建xFormers:
切换到webui根目录
cd repositories
git clone https://ghproxy.com/https://github.com/facebookresearch/xformers.git
cd xformers
git submodule update --init --recursive
pip install -r requirements.txt
pip install -e .
然后你就可以在webui体验了,设置一下parameter参数尽情享用吧!
cd /home/gt/text-generation-webui
python server.py --share --chat --bf16 --xformers








 陕公网安备 61019002002448号
陕公网安备 61019002002448号